Introducing react-busser: Designing for better application data flow in ReactJS — Part 2
Hey there! It’s been a minute since Part 1 right ? I apologize that it has taken this long to get back to it. However, we are here now and i want to share what exactly react-busser brings to the table when it comes to better application data flow and fine-grained reactivity hence, better state management especially at scale. The aim of react-busser is to make ReactJS feel a lot more like SolidJS.
Earlier in 2023, Rich Harris of Svelte and Rollup fame delivered a very spicy tech talk (on YouTube) titled: In my humble opinion where he basically made a couple of statements of opinion, assertions and predictions about the state of frontend web development and one of the most important things he said was:
…Javascript is event-driven while user interfaces are state-driven. Yet, the updates made by user interacting with the user interface is event-driven. There’s an impedance mismatch that UI libraries like ReactJS, AngularJS and/or Svelte introduce themselves or try to make up for in other ways.
This is so true not only about the UI library (ReactJS) but also about any state management solution or library for React. What does this mean ? An impedance mismatch in this sense means that there’s never a 1-to-1 correlation between events triggered in a JavaScript application and the state change effected as a result (especially at higher rates of events triggered or higher number of consecutive state updates linked to an event — i.e higher fan-in).

More often than not, every event triggered within the JavaScript software is usually followed by 2 or more distinct command-based state changes that lead to the final user interface updates. So, one javascript event from a user interaction seldom leads to exactly one state change. It was for this reason that in 2018, the React core team introduced Concurrent mode over Sync mode. More so, this ReactJS approach only makes sense when you are fine with just coarse-grained reactivity. which React offers and can be beneficial in certain cases.
In electrical engineering, an impedance mismatch results in inefficient power transfer from source to destination. This means that the rate of transfer from the source doesn’t match the rate of intake at the destination. Therefore, efficient transfer is difficult to achieve and maintain. Some juice (in the transfer) is wasted in-between. You also have a similar mismatch issue with data stored in databases and the data used in application code on a backend.
Using the examples i have given above, I hope you now understand what i mean by impedance mismatch ?
So, In JavaScript frontend software, this impedance mismatch has to do with unequal mapping of all events generated by a user interacting with a user interface to predictable and expected state changes (or extensive state transitions) executed as a set of commands mapped from each event generated. This unequal mapping shows up in different ways and creates hard-to-follow mental/programming models and other complexities when building user interfaces that force these UIs to rely on coarse-grained reactivity to stay up-to-date (like ReactJS).
These complexities can show up as different kind of bugs that are associated with how side-effects (non-local instructions) around the UI updates can often not translate into the right set and order of state changes for the next UI render. Different UI libraries usually offer varying level of ease for dealing with this complexity and alternative ways it can be managed.
If not managed properly, this complexity can get very unwieldy especially at a larger scale! ReactJS and other UI libraries do not do a good job of providing tools or concepts that properly manage said complexities.This is why we need state flow management to properly align events (and UI interactions) received by ReactJS to the state changes that drive user interface updates.
In the same vein, the consequence of this is that the data lifecycle (based on the data flow within React components) can sometimes become out-of-sync with the ReactJS component lifecycle. What do i mean by this ? Well, the component lifecycle stages are different from that of the data (state) lifecycle stages:
- Mount (sync)
- Update (sync)
- Unmount (sync)
The above is a summarised version of the ReactJS component lifecycle. For data (flow) lifecycle we have:
- Synchronize Data — Mount (async)
- Synchronize UI/Data — Update (async)
- Synchronize Data — Unmount (async)
SolidJS helps to manage/hide this complexity by treating function components as a “one-time setup function” for defining an internal state graph instead of as a blueprint for extracting the next render output throughout the life of the web application frontend as is the case with ReactJS.
When a ReactJS component mounts, the logic inside it has to synchronize all state (UI state and server state) simultaneously after data fetching an display the result on the screen (Synchronize Data — Mount). However, after a component is mounted and has to update due to user interaction, only the UI state continues to be synchronized (until when the server state is updated after a certain point or at certain points). Now, the server state is kept stale while state derived from the server state continues to be managed/updated alongside UI state.
Finally, when the component unmounts, only the server state is synchronized and state synchronization ends (Synchronize Data — Unmount).
Sometimes, when trying to synchronize data from async source, the UI can become unstable and you may have flashes of stale state rendered on the UI. ReactJS does this well enough for simple we apps/sites but doesn’t do this well enough especially for web apps with a very high level of interactivity.
And you are going to see why shortly. Read ahead.
Excessive reliance on a virtual DOM
Here’s an excerpt from the Qwik docs:
The big thing to understand (and the reason vDOM is not a performance problem in Qwik) is that in React when you invalidate a root component the vDOM for the whole tree gets recreated. In Qwik, the decision is made on a per-component basis. And only for components that have structural change AND are actually changing their structure. If a component is structural (vDOM) but no change in structure is detected, then Qwik skips the component. You can think of it as auto-memoization of all components, this means that vDOM is only employed when the view is changing structurally. This is rare because in most cases the view only changes its values.
In short, Qwik uses vDOM, but significantly less than React in comparable situations.
This is a clear indictment on ReactJS in terms of how much it relies heavily on the virtual DOM for state/UI reconciliation.
You see, ReactJS is strong on theory but weak in implementation. The virtual DOM is simply a way to cushion the effect of the overhead recalculating the state and syncing it to the UI. The ReactJS docs will tell you that the virtual DOM is the most efficient way to update the DOM but the docs isn’t being fully upfront about the cost.
There are two primary costs to using a virtual DOM.
- Full in-memory copy of the entire DOM (higher memory use) for just the last render.
- No differentiation between static (hard-coded) and dynamic (not hard-coded) elements within components. Everything is recalculated on demand!
The higher memory usage cost might not mean much on say a desktop computer but on mobile, it means a lot to you (the owner of the ReactJS app) and to your user. In 2020, some research was done into how much memory most UI libraries used at the CPU (i.e. main thread) and ReactJS was by far the highest in said memory usage.
Even when you run page speed tests for both the old and new React docs sites, you can see the differences:
- Old React docs site (mobile — https://legacy.reactjs.org)
- Old React docs site (desktop — https://legacy.reactjs.org)
- New React docs site (mobile — https://react.dev)
- New React docs site (desktop — https://react.dev)
If you take a close look at the results for mobile for both the old and new documentation sites for React, you’ll find that the only metric that significantly got better is Total locking Time (TBT). You will also find that Largest Content Paint (LCP)got slightly worse in the new one. Unlike SolidJS, ReactJS doesn’t spend a lot of time setting a lot of things up on the first render.
I have always been a proponent of not relying on a virtual DOM as from a performance perspective, it is bad for most of your users on mobile. Also, the perceived benefit of having a virtual DOM doesn’t outweigh the cost.
See below the page speed test results for the SolidJS docs site (the overall score for performance was impacted by the INP metric score):
- SolidJS docs site (mobile — https://docs.solidjs.com)
- SolidJS docs site (desktop — https://docs.solidjs.com)
SolidJS has really good numbers for Largest Contentful Paint (LCP) and First Contentful Paint (FCP) on both mobile and desktop. It has a really bad Total Blocking Time (TBT) score because like ReactJS, it spends a lot of time doing work on the main thread just to set things up but once it does, it becomes really fast.
Though these page speed tests do not prove conclusively that SolidJS is always more performant than ReactJS. I believe it does point to the fact that ReactJS delivers a worse user experience on mobile than SolidJS does due to the virtual DOM.
Even, VueJS has just introduced Vapor at VueConf in Toronto in 2023. Evan You stated that the virtual DOM wasn’t the best way to update the real DOM. In fact the virtual DOM inadvertently encouraged a deeply nested UI structure which is always bad for performance. UI structures that aren’t deeply nested but are broader with many more branches from the root component are much more performant on average.
The better alternative is build-time compiled templates (used by VueJS & SvelteJS) which have way more benefits than using a virtual DOM. SolidJS (and sometimes VueJS) works with run-time compiled templates which is not as performant as build-time compiled templates. Finally, ReactJS currently doesn’t do any build-time compilation or any form of compilation either (perhaps we may see such with the advent of the ReactJS compiler — however, the compiler won’t optimize much out of badly written React code).
All of this is very significant!
Re-render Everything (on every state change)…
The main issue i see here is with the ReactJS model of re-rendering everything whenever any piece of state changes. Why is this an issue ? Well, because it messes with state synchronization across a set of separate ReactJS components that should appear to work as a single unit of UI (web page) on the users’ screen. This design which mandates ReactJS to re-render the entire component each time there is a state change is the single most counter-productive aspects of the ReactJS paradigm/working principle and i will explain why in a bit.
Stay with me 🙏🏾 please.
Some people say unnecessary renders are not a huge problem in ReactJS. They say this is because that rendering in ReactJS is highly optimised. In reality, this isn’t entirely true. Rendering in ReactJS has an exponential runtime complexity (O(n ^ n)) simply because a given component and its’ descendants re-render. This means you are paying a cost at runtime for both time and space. This might not seem like much for small web apps but it adds up later as the app gets bigger.
Also, why is a lot of time being spent trying to solve the “problem” of unnecessary renders if it wasn’t actually a problem ? For example, the million.js project has provided a lot of helpers like the block() and <For /> components to improve rendering speeds and avoid wasteful re-renders.
The ReactJS core team is also trying to solve the same problem with the much anticipated release of ReactJS v19 and the ReactJS compiler by the end of 2024.
By re-rendering the entire component each time the state of a ReactJS app changes, we are assuming that all the logic and calculations for the current state need to always be done repeatedly. But, based on the fact that there’s no place for stale data and UI inconsistencies, why does ReactJS itself not optimize for the static and unchanged areas of a components’ re-render ?Instead it puts the bulk of that work on the ReactJS developer, this in turn puts a huge cognitive burden on the engineer to know what parts of the logic should run and which parts shouldn’t run at any time during the re-render phase of each state update to produce the desired output or UI render.
Here’s the kicker: The engineer has to expose that logic (or parts of it) to run at just the right point(s) in the component lifecycle flow else one or more bugs are sure to pop up. Furthermore, the intricate web of stamp coupling that arises from passing all state data as props (to keep one separate ReactJS component in sync with others) as well as the functions that trigger state updates also as props packs a hefty bill of additional complexity to an already complex setup. A consequence of this design is that useState() and useContext() is excessively tied to the component tree updates and its’ lifecycle flow. This further leads to things like excessive prop-drilling and “lifting state” indiscriminately. I don’t even want to get started on the many foot-guns you can encounter with useEffect() and all.
Please, don’t get me wrong here; ReactJS has great concepts that guide its’ working principles and implementation via the following:
- Component-based UI architecture
- Uni-directional Data flow
- Highly Interactive UI
- High Locality of Behavior (LOB)
- Simplified relationship between the domain+data model and view (a small but significant departure from the traditional MVC style featuring a non-existent controller).
These are all the great aspects of ReactJS and i love using it but insisting that ReactJS function components re-run all the logic inside it on every state update as well as utilize props and effects exclusively to keep multiple ReactJS components in sync is where i think the ReactJS core team went too far. Re-rendering everything on each state update is the top reason why the virtual DOM exists in the first place and the source of all the needless complexity that came after — e.g. useMemo(), useCallback() , React.memo() and the likes.
Surely i know, props and effects (i.e. side effects — via useEffect()) do get the job of state synchronization completed well. However, they don’t always do so in a very efficient and error-free manner. For a simple and single parent (e.g. a Compound + Headless UI) component that needs to share its’ state with 2 or more of its’ stateless child components, props and effects are just adequate and perfect for the job.
In fact, the whole re-render everything idea works well here too because, one stateful component is sharing data with it’s stateless children and is not interacting with other stateful components as children or siblings or even parent. But when other stateful children and sibling components doing async stuff become a part of the equation, re-render everything becomes a freaking nightmare!
In the days of class components, this whole “re-render everything” wasn’t that much of an issue, because only the render() method was being called on every state update/re-render. However, as soon as we stepped into function components land, everything became worse as the entire function (component) was being run all over again (apart from useState() retaining it’s new value just before the re-render and useEffect() only running it’s callback at specific times) on every re-render.
Also, every component-based UI library out there provides 2 things to enable us build highly interactive user interfaces:
1. A state graph (a dependency tree of all the state displayed on all web app UI)
2. A component graph (the component tree)
Below you can see the differences between the model of reactivity for SolidJS and ReactJS.
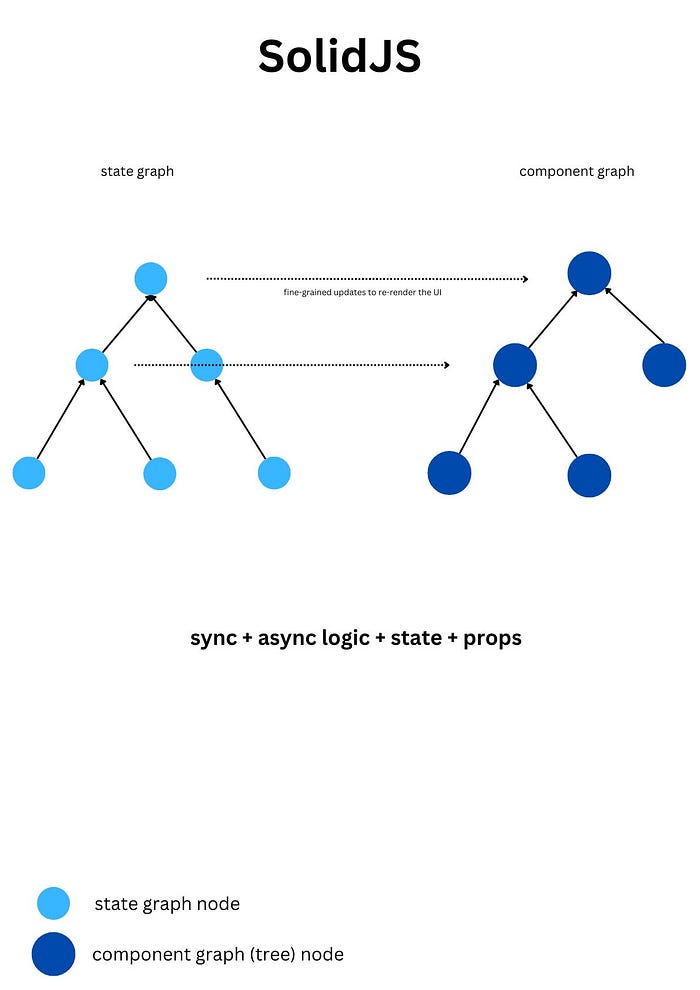
The effect of this might look trivial but it’s not. Over time, the little extra re-renders all around the component tree begin to create a ripple of unwanted re-renders as the ReactJS codebase grows. React says it has to err on the side of too many re-renders because it doesn’t want to show UI with stale or out-of-date state (which is good). But, there are better ways to keep the UI in sync with state without tightly coupling the data model (state graph) updates and UI view model (component graph) updates like SolidJS does (See above 👆🏾👆🏾).

Like i mentioned in Part 1, the ReactJS model (depicted above in the picture) falls apart when you throw in async into the mix. SolidJS does a very good job of separating the state graph from the component graph. This makes it easy to update the component graph with fine-grained reactivity from the state graph without much overhead.
There are two additional benefits to separating the state graph from the component graph:
- No need for a virtual DOM at all.
- No need for more than 2 lifecycle methods/hooks (mount & unmount).
The depth of the component tree for a React app can also affect the speed and performance of ReactJS on the frontend. I have suggested “pruning the leaves” of the component tree in order to reduce prop drilling and slow re-renders.
So, the idea of “pruning the leaves” encourages ReactJS developers (who use react-busser) to create less deeply nested component trees and more broader component trees (as stated earlier). In other words, create less child components deep into the tree overall and instead create more sibling components.
In short, what react-busser is built to achieve is using tiny abstractions to make ReactJS behave a little more like SolidJS. In other words, organizing rendering logic around data flow than around control flow. ReactJS organizing the rendering logic around control flow is a “messy situation” in my opinion.
So, react-busser makes the best out of what i refer to as a “messy situation”. react-busser maximizes the use of a single event bus for most of the state synchronization and state flow (through the web app) while minimizing the excessive use of props and effects. This is done so that only the component (or sub component tree) that needs to re-render actually does.
On to the next on 👇🏾
Lifting or Lowering State (just to share access to state)…
This is considered the golden advice for building React apps that require the sharing and syncing of state across many components across the application. By simply lifting state to a common ancestor (parent component), we can control all child components and it’s very easy to achieve. Lifting state works most of the time. However, lifting state doesn’t come without cost. For a simple app with very few moving parts, that cost is minimal or negligible at best. But as the application scales in size, complexity and frequency of state updates, the costs ramp up and starts to affect performance.
The costs includes the following:
- It directly causes lots of useless and unnecessary re-renders down the component tree
- It encourages creating God components, prop drilling or other issues.
- It rightly reduces the surface area for debugging logic errors but it increases the surface area for debugging data flow and update errors by increasing the distance between where the data/state is created/aggregated and where it’s used/updated/needed which can lead to uncontrolled error propagation.
- component complexity and reusability are put in opposing sides with a direct relationship (i.e. increasing reusability also increases complexity).
- Potential Overload of a Parent Component higher up the the component tree.
Lets’ start with coupling; Lets’ be honest; lifting state up can sometimes reduce coupling (i.e. improve cohesion) and increase reusability. This happens when a component receives data for which it owns all the logic working on that data. However, it can also introduce tighter coupling between components that don’t always go together. Child components become dependent on the state and behavior of their parent component. This can reduce the reusability of the child components and make it more difficult to modify, replace or reuse them in the future without affecting the parent component code. Also, If multiple child components require state management, lifting all the state up to a single parent component can overload it with too much responsibility. This can lead to a bloated and less maintainable parent (God) component.
Here’s an example:
Furthermore, lifting state up and up can (more times than not) result in unnecessary re-rendering of other components. When the state is updated in the parent component, all child components that receive the state as props will re-render, even if they don’t actually depend on that specific state change. This can potentially impact the performance of the application.
At some point it becomes confusing to decide when to lift or drop state because the data dependence requirement dictated by a component subtree or subtrees has changed. Yet, if you must share the state with other components, then you must lift it but then drop it only when sharing state is causing a performance problem.
react-busser makes it easy not to limit the confusion about whether to lift state or not. You can share state between components at any level within the component tree.
react-busser insists that any React component that controls a given piece of state (using calls to setState(...) ) will also own that state (i.e. the component will contain the useState() hook definition). Therefore, to share the state with other components we simply broadcast (i.e. communicate) it after signalling an event. However, there are situations where data is loaded from the server and so the above won’t apply completely.
Data flow model for react-busser paired with react-query (@tanstack/query)

The above diagram depicts the relationship between transient data and non-transient data and how each makes up the VIEW MODEL and DOMAIN MODEL respectively. The DOMAIN MODEL is where non-transient data is managed from and to the server-side. The VIEW MODEL is where transient data is managed within the client-side. The reason why react-busser exist is to help manage the non-transient data that flows out from react-query into a React component and prepare transient data to be fed back into react-query.
Data ought to flow without restriction across the UI for the frontend to be efficient, performant and reliable!
We know that UI changes are usually a function of state changes (from Part 1):
UI = f(state)
Or as Dan Abramov states in his latest blog post anticipating ReactJS v19, it’s more like:
UI = f(client-state, data) + f(server-state, data)
Now, both are correct equations for the UI. However, ReactJS calls f(state) excessively by re-rendering on every single state change. If you remember in Part 1, i said calling f(state) less increases performance.
ReactJS claims to be wholly reactive but it really isn’t because ReactJS is by definition a tree of strictly interactive components, imperatively controlling and communicating with other one another (coarse-grained reactivity). This creates a restriction for the pathways that data can travel in the web application.
This is what react-busser offers. A simple way to ensure data flows freely and unrestricted through different components using events and true reactivity.
Over-reliance on React for managing all manner of state
I might suggest at this point that it’s important to pause and watch this 18 minute talk before you continue reading (or bookmark it for later).
Any javascript application/software running inside a browser has a number of places to store state, mutate it and get it back. In the cases where React is used to create this javascript application/software, React encourages you albeit indirectly to rely heavily on this.setState()/useState() as the sole way to manage both transient state and non-transient state. After all, the official React Docs even says this:
In most cases, we recommend using controlled components to implement forms. In a controlled component, form data is handled by React. The alternative is uncontrolled components, where form data is handled by the DOM itself.
This ought not to be so. Why ? Because, this.setState()/useState() is poor at handling all possible types of application state due to the fact that it triggers re-rendering every time. It’s only best for presenting updated state on the UI that is very likely to change sooner or later especially state with a low cardinality (data that has a very limited range of values and doesn’t change often). For data with high cardinality, you can simply use the DOM attributes or URL query params or any other thing that side-steps the the VDOM entire e.g. signals. However, some React eggheads refer to this as an “anti-pattern”, simply because React state is not used— quite regrettable.
In similar scenario where a form is created in a React application, the form input state is already being stored within the DOM (text input value attributes accessible by JavaScript) and that’s enough. I mean, it should be enough right ? It has always been a problem for me that a HTML Form in React re-renders on every character keystroke (UI state) because of this.setState()/useState()triggering a re-render. To me, this is maddening and has been for a long time. That’s why i so much love the direction which @remix_run and @HookForm are taking in this regard which is: Not using this.setState()/useState() for everything especially forms.
Like i stated earlier, there are other places that can store and mutate state well enough namely:
- DOM (attributes)
- URL (query params)
- Memory (temporary variables)
- Storage (e.g.
localStorage)
this.setState()/useState() shouldn’t be used for everything especially for setting CSS styles that hide some DOM node or set some offset position.
There are also problems that can arise from using this.setState()/useState() for everything especially UI state (visibility state) for widgets like Dropdown Menus and Modals. One can comfortably utilize useRef() for these purposes.
Take a look at these 2 examples of an implementation of a <Dropdown /> React component(s).
The one which uses useState() to toggle the visibility of the floating menu is more error prone than the one that doesn’t (uses useRef() instead). Apart from the fact that doing it this way stops you from being able to apply things like animations and keys to the JSX, it also makes your UI janky when the virtual DOM has to switch.
More-so, the onChange handler is functions wrongly (called twice sometimes at random) when useState() is used to handle DOM element visibility of the dropdown. However, the same onChange handler functions correctly when useRef() is used to handle the DOM element visibility of the dropdown.
It’s better to store the UI state for the visibility in the DOM rather than in useState() .
Reactive “MVC” or Partially-reactive MVI — react-busser concepts
Now, react-busser is reactive alternative to the interactive model found in the way React works already. ReactJS makes use of imperative command-driven interactive APIs like setState(...) to drive UI updates. react-busser uses a different approach to this interactive model which is the reactive model (using an event bus to communicate shared data across multiple React components).
In this way, multiple components (objects) can operate simultaneously on the same piece of state, instead of constantly and imperatively synchronizing multiple local states across many other components.
I put “MVC” in quotes because what i want to describe here isn’t really MVC per say. Furthermore, mixing any form of reactivity with MVC results in extreme chaos. In fact, implementing any form of MVC on the UI (frontend) is also a recipe for disaster.
What i wish to describe here is MVI (Model-View-Intent). So, therefore partially-reactive MVI.
You see recently, i started learning Golang and i employ the effective go website to help me learn. In the section on Concurrency, there’s this saying:
Do not communicate by sharing memory; instead, share memory by communicating
This is the basis of how react-busser works at its core, unlike Redux and Zustand that communicate by sharing memory (or sharing the store that contains the data to different ReactJS components), react-busser shares memory by communicating (or sharing the data via an event bus to different ReactJS components instead of the store). This enables state to be updated in a predictable and synchornized manner. But more importantly, it ensures that changes made later to state (e.g displayed on the UI or needed to derive other state) are not overwritten by other changes earlier which the second update was unaware of. This could happen if the the second update doesn’t check for the sign of an earlier update.
It also means that data isn’t managed or stored outside of the React components that owns it (where the data is managed (i.e. created and updated) not where it’s loaded) which can lead to coupling. Here’s an article about how Zustand messes with how React works.
Although, react-busser partially opts out of this model when dealing with using the useSharedState() hook. The useSharedState() hook should only be used when you wish to cache on the client-side existing server state that is usually updated in full (never appended to or modified in part) from many places (i.e. ReactJS components) and displayed in many others (usually after it has been modified on the server-side).
An example of this kind of state is the common user object in a given SPA ReactJS application (in a server-rendered ReactJS app, the state for user will be managed solely on the server-side — no need for the useSharedState() hook in this case). For instance, the user object can be updated via a form which submits data to the server-side and afterwards cached on say localStorage . useSharedState() should not be used for UI state that changes often. It should simply be used for caching and synchronizing Server-state in a SPA.
When it comes to transient state, there are two types:
- Transient state that flows into being Non-transient by being persisted on the server.
- Transient state that doesn’t flows into being Non-transient but remains the way it is and is deleted when the browser session dies.
The first type (the view-model) is handled well by react-busser. However, react-busser doesn’t handle the second type at all. It leaves that to a library like react-query.
Data logic is split between react-busser and react-query and managed separately. So, react-query manages the non-transient state while react-busser manages transient state. The state react-busser handles is always transient until it is handed over to react-query to be formatted and sent to the server to be persisted.
Similarly, when persisted state is fetched from the server, react-query hands over the non-transient state to react-busser and it becomes transient.
You can read up more about how react-busser can be used:
Thanks for reading!
